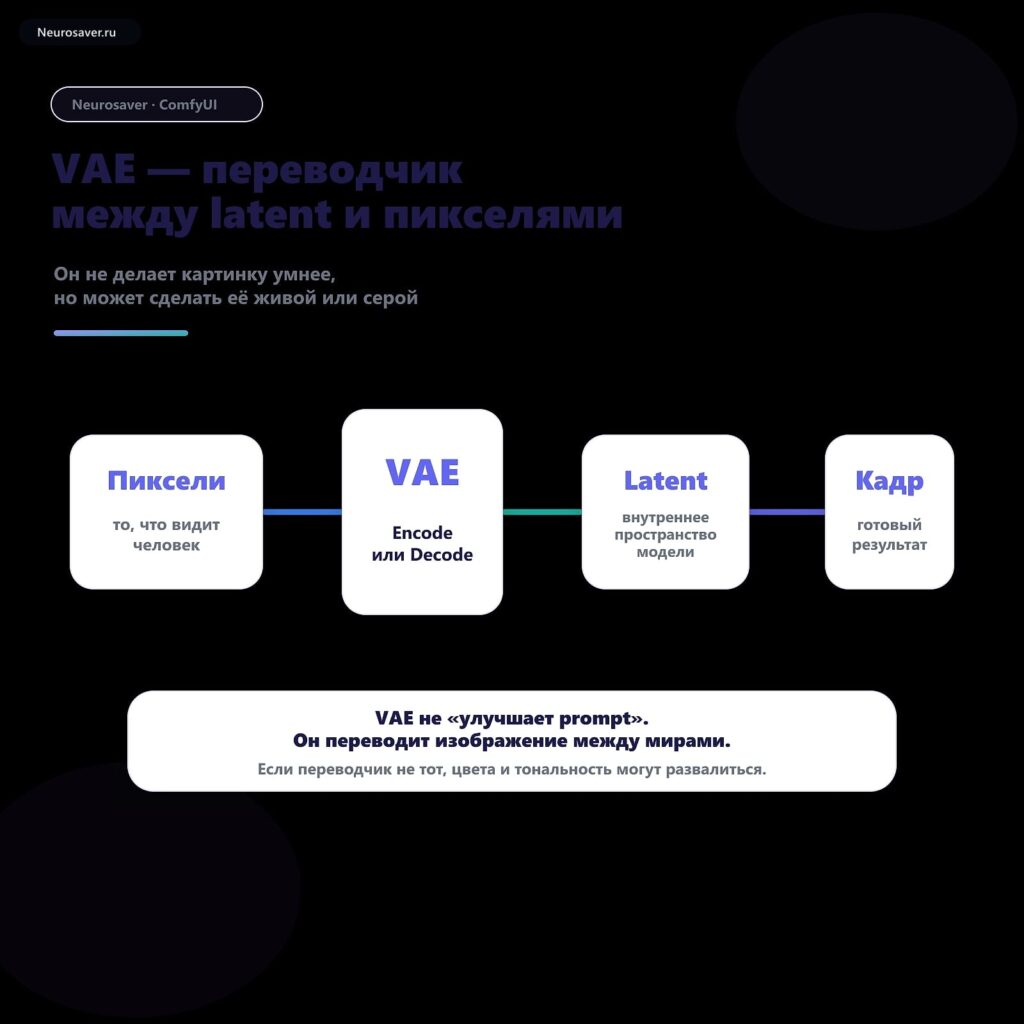
VAE
variational autoencoder — сжимает картинку в латент и обратно
VAE (Variational Autoencoder) — это пара нейросетей внутри Stable Diffusion, SDXL и FLUX, которая сжимает картинку в компактное представление и раскрывает его обратно. Encoder превращает изображение 512×512×3 в латент 64×64×4 — в 48 раз меньше данных. Decoder делает обратное превращение. Сама диффузия работает в латенте, а не в пикселях — иначе генерация заняла бы часы. Кроме того, выбор VAE влияет на цвета и контраст финала.
Коротко
Коротко. VAE — это «переводчик» между пикселями и латентом. В Stable Diffusion вся работа идёт не на самой картинке (несколько миллионов чисел), а на её сжатой версии — латенте (несколько тысяч чисел). VAE Encoder сжимает картинку в латент, VAE Decoder разворачивает его обратно. Замена VAE на «улучшенный» — известный способ исправить выцветшие цвета и серую гамму на старых моделях SD 1.5.
Что это такое
Декабрь 2021-го. Группа исследователей LMU Munich публикует работу «High-Resolution Image Synthesis with Latent Diffusion Models». Главная идея: диффузию слишком дорого считать на пикселях — 512×512×3 это три миллиона значений на одну картинку. Если предварительно сжать картинку в маленькое пространство, считать в нём, а потом разжать — генерация ускорится в десятки раз.
Сжимателем стал классический Variational Autoencoder. Это связка из двух нейросетей: одна (Encoder) учится переводить картинку в маленькое представление, другая (Decoder) — восстанавливать из представления исходную картинку. Тренировка идёт парой: «зашифровал → расшифровал → должно получиться так же».
В Stable Diffusion VAE — отдельная маленькая нейросеть на 84 миллиона параметров (для SD 1.5). Она вшита в модель и обычно идёт незаметно. Но при желании её можно подменить на другую — например, на «улучшенный» VAE-ft-mse, который добавил насыщенности к выцветшим картинкам SD 1.5.
Как это работает
Цикл генерации в Stable Diffusion с участием VAE выглядит так:
- Промпт через CLIP кодируется в эмбеддинг.
- Шум 64×64×4 случайным образом инициализируется (это латент).
- U-Net за 20–30 шагов убирает из латента шум, ведомый эмбеддингом промпта.
- VAE Decoder разворачивает чистый латент 64×64×4 в картинку 512×512×3 (для SD 1.5).
Сжатие в SD 1.5 — в 48 раз:
картинка: 512 × 512 × 3 = 786 432 числа
латент: 64 × 64 × 4 = 16 384 числа
В SDXL латент 128×128×4 (для картинки 1024×1024), коэффициент сжатия тот же.
В img2img VAE используется дважды: Encoder превращает входную картинку в латент, U-Net дорабатывает её по промпту, Decoder выдаёт результат. Это и отличает img2img от чистого txt2img.
Для FLUX и SD 3 используется другой VAE: в латенте обычно 16 каналов вместо 4, поэтому в нём остаётся больше информации о фактуре, мелких деталях и тексте. Пространственная сетка всё ещё меньше исходной картинки, но сами латенты устроены иначе. Поэтому SDXL-VAE не подходит для FLUX и наоборот.
Пример на практике
Фотограф работает с моделями SD 1.5 пейзажного направления — Realistic Vision, DreamShaper, Juggernaut. Замечает: цвета выглядят выцветшими, особенно небо и зелень. Серая дымка, словно картинка через грязное стекло.
Решение — подключить vae-ft-mse-840000-ema-pruned.safetensors. Это улучшенный VAE, который Stability AI выпустила специально для исправления цветовой деградации в SD 1.5. Картинки за тот же seed на той же модели становятся насыщеннее и контрастнее: небо синее, зелень глубже, тени плотнее.
В AUTOMATIC1111 VAE подключается в Settings → Stable Diffusion → SD VAE. В ComfyUI — отдельным узлом Load VAE → подключить к VAE Decode. В Forge — там же, где в A1111.
Для SDXL стандартный sdxl_vae.safetensors (или встроенный, идущий с базовой моделью). В моделях типа Juggernaut XL VAE уже встроен и менять его не нужно.
Если вы пришли из ComfyUI
В ComfyUI VAE обычно замечают не тогда, когда всё хорошо, а когда картинка внезапно стала серой, мыльной, слишком контрастной или вообще превратилась в шум. Визуально это похоже на поломку модели, но часто причина проще: workflow декодирует латент не тем VAE.
Минимальные маршруты такие:
Load Checkpoint→KSampler→VAE Decode→Save Imageдля обычного txt2img.- Входная картинка →
VAE Encode→KSampler→VAE Decodeдля img2img и inpainting. Load VAE→VAE Encode/VAE Decode, если нужен внешний VAE вместо встроенного в checkpoint.
Быстрая диагностика:
| Симптом | Где искать | Что сделать |
|---|---|---|
| Серая или блеклая картинка | VAE Decode |
подключить VAE от этой модели |
| Ядовитые цвета | checkpoint + VAE | вернуть встроенный VAE |
| Шум вместо изображения | тип модели | не смешивать SD 1.5, SDXL и FLUX |
| img2img теряет форму | VAE Encode + denoise |
снизить denoise и проверить размер |
| После апскейла всё плывёт | второй проход | проверить VAE и denoise в Hires.fix |
С чем часто путают
- VAE и Encoder / Decoder — VAE это пара encoder+decoder. Encoder сжимает, Decoder разжимает. В тексте часто говорят «VAE» сразу про обе части.
- VAE и U-Net — U-Net это главная нейросеть, которая убирает шум. Она работает в латенте. VAE — переводчик между латентом и пикселями. У них разные задачи.
- VAE и CLIP — CLIP кодирует текст в эмбеддинг. VAE кодирует картинку в латент. Совершенно разные модели с разной целью.
- «Прошитый VAE» и «внешний VAE» — у моделей вроде SDXL VAE встроен в файл checkpoint. У некоторых SD 1.5-тюнингов нужно подключать VAE отдельно. Если картинки выглядят серыми, чёрно-белыми или с артефактами — часто проблема именно в VAE.
Частые ошибки и заблуждения
- «VAE влияет только на цвета». Не только. Он определяет, как высокоуровневое представление превращается в пиксели: текстура кожи, чёткость лиц, мелкие детали. Замена VAE может улучшить или ухудшить все эти аспекты.
- «Замена VAE даст другую картинку». В большинстве случаев — нет. Структура и композиция остаются те же, потому что они определяются U-Net в латенте. Меняется только финальная отрисовка пикселей.
- «VAE — это та же модель, что и Stable Diffusion». Нет. Это отдельная нейросеть, которая поставляется вместе с SD, но запускается на разных этапах.
- «VAE забирает много VRAM». Не сильно. SD 1.5 VAE — 84M параметров, ~330 МБ в FP16. SDXL VAE — около 250M параметров. Это в десятки раз меньше U-Net, на VRAM почти не влияет.
- «Можно тренировать свой VAE». Технически да, но почти никто не делает: тренировка VAE требует огромного датасета и сравнима по сложности с тренировкой всей модели. На практике используют публичные VAE.
Связанные термины
- ComfyUI — позволяет подключать VAE отдельным узлом и подменять под задачу.
- ComfyUI с нуля — практический workflow, где VAE Decode стоит в финальной части генерации.
- KSampler — работает с латентом, а потом отдаёт его в VAE Decode.
- Latent Space — пространство, в котором VAE кодирует картинку.
- Denoising Strength — определяет, насколько сильно KSampler меняет латент в img2img.
- img2img — сценарий, где VAE Encode и VAE Decode нужны одновременно.
- Hires.fix — второй проход генерации, где VAE и denoise часто влияют на финальную резкость.
- CLIP — текстовый энкодер, не путать с VAE.
- Stable Diffusion / SDXL / FLUX — у каждого семейства свой VAE с разными характеристиками.
Частые вопросы
Нужно ли скачивать VAE отдельно? Для SDXL и FLUX — обычно нет, VAE встроен в checkpoint. Для SD 1.5 — часто да: тюнинги вроде Realistic Vision рекомендуют подключать vae-ft-mse для лучших цветов.
Где скачать VAE?
Hugging Face (репозитории stabilityai/sd-vae-ft-mse-original, madebyollin/sdxl-vae-fp16-fix), CivitAI (раздел VAE). Файлы маленькие — 100–300 МБ.
Какой VAE использовать для SD 1.5?
Стандартный — vae-ft-mse-840000-ema-pruned.safetensors. Для аниме-моделей — kl-f8-anime2.ckpt или vae-ft-mse, разница незаметная.
Почему мои SDXL-картинки чёрные / содержат NaN?
Чаще всего — старая версия sdxl_vae в FP16 со встроенным багом NaN. Решение — поставить sdxl-vae-fp16-fix.safetensors от madebyollin или переключиться в FP32.
Можно ли использовать VAE для апскейла? Нет, для апскейла есть отдельные модели (RealESRGAN, 4x-UltraSharp, SUPIR). VAE работает только в паре с U-Net и латентом.
В чём отличие FLUX-VAE от SDXL-VAE? FLUX-VAE имеет 16 каналов в латенте (вместо 4 в SDXL), что даёт больше информации на каждый пиксель латента. Это позволяет рисовать читаемый текст и тонкие детали. Но и веса несовместимы с SD-моделями.
Что такое VAE в ComfyUI? Это узел Load VAE, который подключается к VAE Decode. По умолчанию ComfyUI берёт VAE, встроенный в checkpoint, но через Load VAE можно подставить внешний — например, vae-ft-mse для SD 1.5 или sdxl-vae-fp16-fix для SDXL.
Почему картинка в ComfyUI стала серой?
Чаще всего workflow использует неподходящий VAE или вообще не получает корректный VAE из checkpoint. Проверьте, куда идёт выход vae из Load Checkpoint: он должен попадать в VAE Decode, а для img2img ещё и в VAE Encode. Если подключён отдельный Load VAE, убедитесь, что он подходит именно к SD 1.5, SDXL или FLUX.
Можно ли удалить Load VAE из чужого workflow?
Не спешите. В некоторых workflow внешний VAE стоит не для красоты, а потому что checkpoint без него даёт серую гамму, NaN или слабые цвета. Сначала сохраните копию, прогоните один seed с Load VAE и без него, а уже потом решайте.
Главное
VAE — невидимый переводчик внутри диффузионных моделей: без него генерация работала бы в 50 раз медленнее. Обычно он не требует внимания, но если картинки выглядят серыми, чёрными, пересвеченными или с цветовыми артефактами — проверьте VAE одним из первых. Для SD 1.5 чаще берут vae-ft-mse, для SDXL — встроенный или sdxl-vae-fp16-fix, для FLUX — собственный 16-канальный. В ComfyUI это отдельная линия workflow: vae из checkpoint или Load VAE должен попасть в VAE Decode, а в img2img — ещё и в VAE Encode.
Большие разборы по теме
Все разборы →
Custom Nodes в ComfyUI: как ставить, чинить и не сломать workflow
Custom Nodes в ComfyUI — это расширения, которые добавляют в граф новые узлы: видео, апскейл, IP-Adapter, ControlNet-утилиты, работу с файлами, UI-панели и…
VAE в ComfyUI: почему картинка стала серой и как вернуть цвет
VAE в ComfyUI — это модель-переводчик между пикселями и latent space. VAE Encode превращает изображение в latent для img2img и inpainting, а…
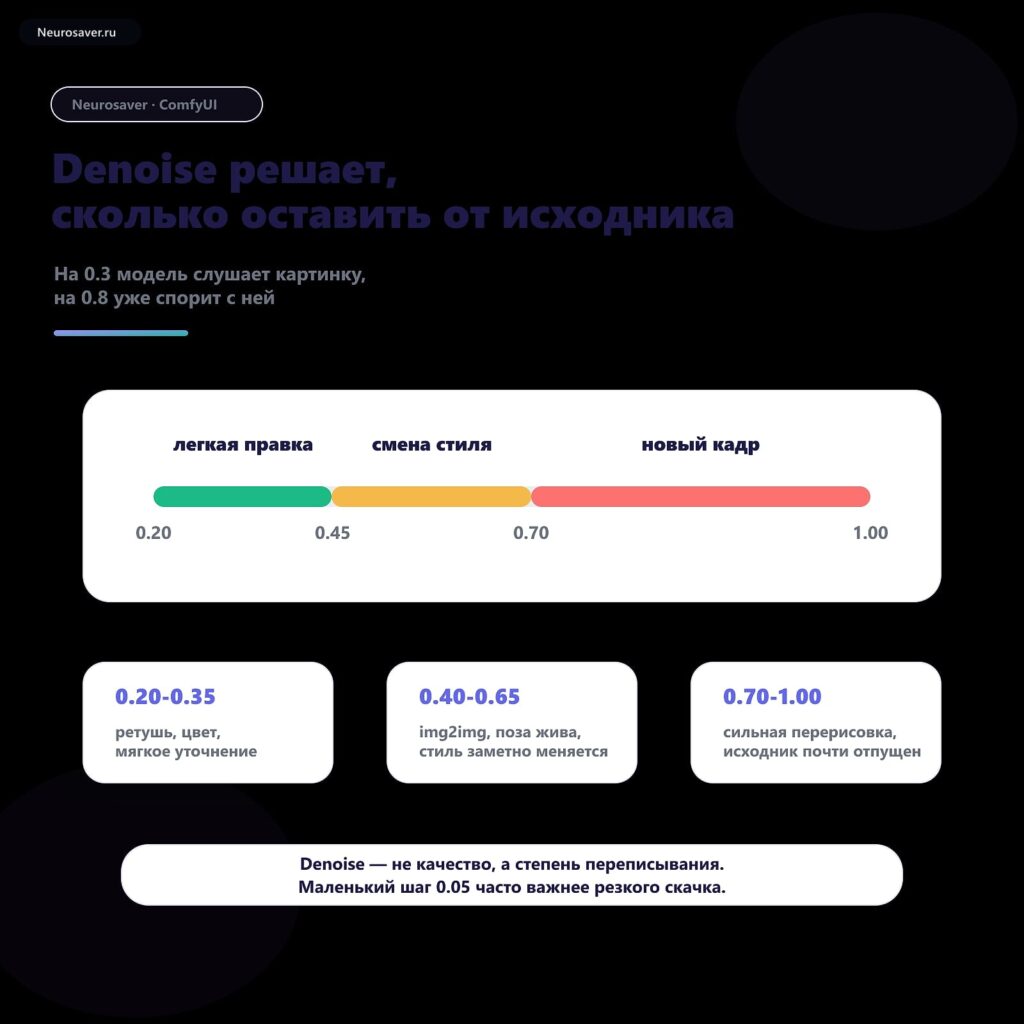
Denoising Strength в ComfyUI: как менять картинку и не убить исходник
Denoising Strength в ComfyUI — это сила, с которой KSampler переписывает входной latent. В text-to-image denoise обычно равен 1.0, потому что модель…
