Embedding
embedding — вектор смысла для слова, фрагмента текста или картинки
Embedding (эмбеддинг) — это длинный вектор чисел, который представляет смысл слова, фразы, документа или изображения. Близкие по смыслу объекты получают близкие вектора. Это позволяет искать по смыслу, а не по ключевым словам, кластеризовать документы и сравнивать тексты на любом языке. На embedding'ах построены семантический поиск, RAG, рекомендации и кросс-модальный поиск «текст ↔ картинка».
Коротко
Коротко. Embedding — это вектор из сотен или тысяч чисел, в который превращается слово, фраза, документ или изображение. Близкие по смыслу объекты получают близкие вектора: «кот» и «котёнок» рядом, «кот» и «автомобиль» далеко. На этом построены семантический поиск, RAG, кластеризация документов и сопоставление текста и картинок. Embedding-модели часто маленькие (десятки–сотни мегабайт) и быстрые.
Что это такое
Поисковая строка: «как уменьшить размер модели для слабой видеокарты». Классический поиск ищет точные слова: «уменьшить», «размер», «модели». Документы про «квантизацию» или «pruning» в ответ не попадут — там нужных слов нет.
Семантический поиск работает иначе. Запрос превращается в вектор (1536 чисел для OpenAI ada-002, 768 для bge-small). Документы в базе тоже хранятся как вектора. Поиск ищет те, чьи вектора ближе всего к вектору запроса. Слова разные — смысл близкий — нужные документы находятся.
Это и есть embedding в действии. Произвольный текст — будь то слово, абзац или целая статья — превращается в точку в многомерном пространстве. Координаты этой точки описывают «смысл» объекта так, как его видит модель. Чем ближе точки, тем ближе смысл.
Идея старая: word2vec появился в 2013-м, GloVe — в 2014-м. Но настоящий взлёт начался в 2018-м с BERT, который дал контекстные эмбеддинги (одно слово в разных предложениях получает разные вектора). К 2024-му эмбеддинги — фундамент RAG, семантического поиска, кластеризации и кросс-модальных задач.
В большом разборе «RAG и AI-поиск в 2026» embedding показан не как абстрактная математика, а как рабочий этап: документ режется на куски, каждый кусок получает вектор, после этого поиск может находить смысл, даже если слова в запросе и документе разные.
Как это работает
Embedding-модель — это обычно небольшая нейросеть (transformer без output-projection), обученная так, что близкие по смыслу пары текстов получают близкие вектора.
Жизненный цикл одного embedding'а:
- Вход. Произвольный текст: слово, фраза, абзац (обычно до 512 токенов).
- Токенизация. Текст режется на токены.
- Forward pass через embedding-модель. Внутри — слои трансформера, на выходе — вектор фиксированной длины.
- Нормализация. Часто вектор делится на свою длину, чтобы все embedding'и были на единичной сфере — упрощает сравнение через косинусное расстояние.
Размерность вектора зависит от модели:
| Модель | Размерность | Размер модели |
|---|---|---|
| word2vec | 300 | ~1 ГБ (Google News) |
| sentence-transformers (MiniLM) | 384 | 80 МБ |
| OpenAI text-embedding-3-small | 1 536 | API only |
| OpenAI text-embedding-3-large | 3 072 | API only |
| bge-large-en | 1 024 | 1.3 ГБ |
| CLIP (text + image) | 512 | 1.7 ГБ |
Сравнение двух embedding'ов: чаще всего косинусное расстояние:
similarity = dot(A, B) / (|A| · |B|)
Результат — число от -1 до 1. Для нормализованных эмбеддингов — от 0 до 1. Близкое к 1 = очень похожие; близкое к 0 = слабо связаны.
Что мощно: семантическая близость работает между языками и модальностями.
- «кот» (русский) → почти такой же вектор, как «cat» (английский) в многоязычных моделях.
- Фотография кота → почти такой же вектор, как текст «cat» в моделях типа CLIP.
- «уменьшить размер модели для слабой видеокарты» → близко к статье про «квантизацию», даже если в ней нет слов «уменьшить» и «слабой».
Пример на практике
Видеомонтажёр собирает «семантический поиск по своим заметкам» — 3 года Markdown-файлов про проекты, монтаж, оборудование. Хочет искать по смыслу, а не по точным словам.
Стек:
- Embedding-модель:
bge-small-en-v1.5(мультиязычная, 130 МБ, размерность 384). Бесплатно, локально на CPU. - Векторная БД: ChromaDB (можно начать с in-memory). Запускается одной командой.
- Пайплайн индексации:
- Прочитать все .md файлы.
- Разбить на куски по 500 токенов.
- Для каждого куска посчитать embedding.
- Сохранить вектор + текст в Chroma.
- Пайплайн поиска:
- Запрос пользователя → embedding.
- Найти top-5 ближайших векторов из Chroma.
- Вернуть тексты этих кусков.
Запрос: «как я в прошлом году настраивал звук для интервью». В прямом поиске Markdown'а ничего не нашлось бы — заметки могут содержать «микрофон», «де-эссер», «компрессия», но не «звук для интервью». Семантический поиск находит их за секунду: вектор запроса близок к векторам этих фрагментов.
В ComfyUI всё то же собирается визуально — нода CLIP Text Encode или специализированная embedding-нода превращает текст или картинку в вектор, дальше нода Cosine Similarity сравнивает с базой. Тот же подход — и текст→текст, и текст→картинка, и картинка→картинка.
С чем часто путают
- Embedding и токен — токен это id из словаря. Embedding — это вектор смысла. У каждого токена есть свой embedding (look-up таблица в LLM), но «embedding» как термин чаще означает вектор для текста целиком.
- Embedding и feature vector — feature vector в классическом ML обычно сконструирован человеком (например, [возраст, доход, длина]). Embedding — выучен моделью; отдельные числа в нём не интерпретируются.
- Embedding и hash — hash это уникальный детерминированный отпечаток, не несущий смысла (близкие тексты дают разные хеши). Embedding — мягкий: близкие тексты дают близкие вектора.
- Embedding и vector database — embedding это объект (вектор). Vector database — хранилище таких объектов с поиском по близости.
- Embedding и LoRA — LoRA в diffusion это адаптер для модели, не вектор. В Stable Diffusion слово «Embedding» исторически означает Textual Inversion — это отдельный концепт, см. ниже.
Частые ошибки и заблуждения
- «Embedding == текст обратно». Вектор нельзя «расшифровать» обратно в исходный текст. Из embedding'а нельзя восстановить точное содержание. Можно только сравнивать с другими векторами.
- «Embeddings одной модели совместимы с другой». Нет. Каждая модель создаёт свои вектора в своём пространстве. text-embedding-3-small и bge-small-en — это разные пространства, их вектора нельзя сравнивать напрямую.
- «Чем выше размерность — тем лучше». Не всегда. 384 для bge-small может работать не хуже 3072 для text-embedding-3-large на конкретной задаче. Стоит измерять, а не выбирать «больше = лучше».
- «Достаточно одного embedding'а для документа любой длины». Длинные документы (>1000 токенов) надо чанковать: embedding целого PDF теряет деталь. Стандарт — куски по 200–500 токенов с overlap'ом 50.
- «Embedding отражает истину». Он отражает то, на чём модель училась. На редких языках или специфичных доменах качество может проседать.
Связанные термины
- Vector Database — хранилище и поиск по embedding'ам.
- RAG — основной use-case embeddings: поиск релевантных кусков перед генерацией.
- Semantic search — поиск по смыслу через embeddings.
- CLIP — модель, делающая embedding и текста, и картинки в одно пространство.
- Cosine similarity — стандартная метрика близости двух embedding'ов.
- Chunking — разбивка длинных документов перед embedding'ом.
- Reranking — пере-сортировка найденных embedding'ов через более точную модель.
- Textual Inversion — особый embedding в Stable Diffusion, не путать с обычным.
Частые вопросы
Сколько занимает один embedding в памяти? Размерность × 4 байта (FP32) или × 2 байта (FP16). Для 1536-мерного embedding'а — 6 КБ или 3 КБ. На миллион документов нужны гигабайты, но не терабайты.
Где брать embedding-модель? Hugging Face MTEB Leaderboard — рейтинг open-source моделей. Для production — OpenAI text-embedding-3-small (платный API, $0.02 / 1M токенов) или Cohere embed-multilingual.
Можно ли искать русский запрос по английским документам? Да, если использовать многоязычную модель: bge-m3, mE5, paraphrase-multilingual-MiniLM. На моноязычной (например, ada-002) качество кросс-языкового поиска ниже.
Сколько документов можно проиндексировать локально? На ноутбуке с 16 ГБ RAM и SSD — 1–5 миллионов в Chroma или Qdrant в режиме compute-CPU. Для бóльших объёмов — облачные сервисы.
Как обновлять индекс при изменении документов? Перепосчитать embedding изменённых кусков, обновить в БД. Поддерживается во всех vector databases. Полная переиндексация нужна только при смене embedding-модели.
Главное
Embedding — это «координаты смысла» для произвольного объекта. Из этой простой идеи выросла большая часть современного AI-поиска: вместо точного совпадения слов модель ищет соседей в многомерном пространстве. На embedding'ах работают RAG, рекомендации, кросс-модальный поиск и кластеризация. Размерность и качество модели влияют на результат; для большинства задач хватает open-source решений на десятки мегабайт. Понимая, как устроен embedding, проще строить надёжные пайплайны поиска и не путать его с другими понятиями.
Большие разборы по теме
Все разборы →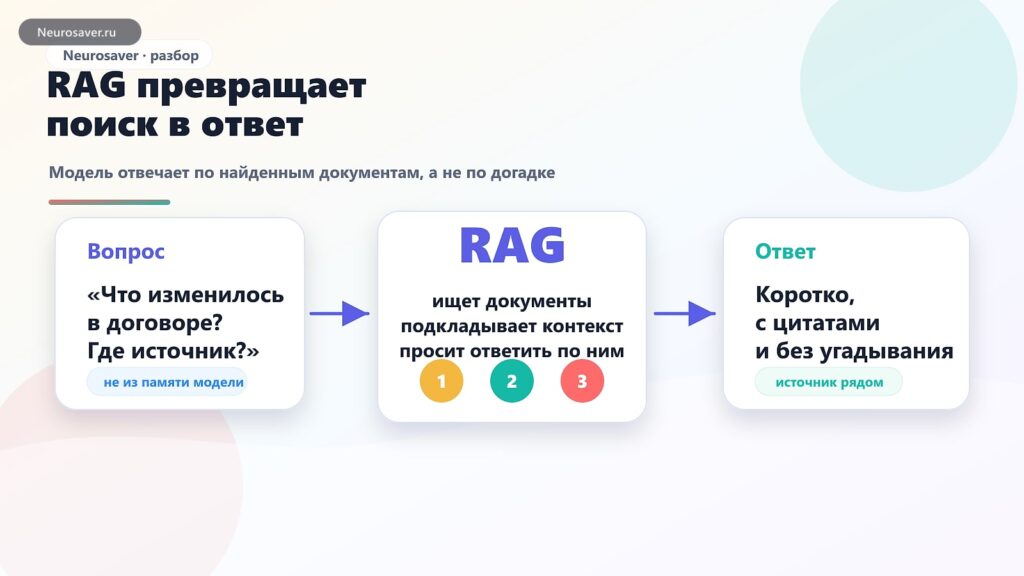
RAG и AI-поиск в 2026: как нейросети отвечают по вашим документам, а не гадают
RAG — это способ подключить языковую модель к реальным документам: сначала система ищет подходящие фрагменты в базе знаний, потом модель отвечает по…

LLM простыми словами: разбор как работают ChatGPT, Claude и Gemini
Большая языковая модель — это нейросеть, которая прочитала почти весь интернет и научилась предсказывать следующее слово настолько хорошо, что выглядит как собеседник.…
